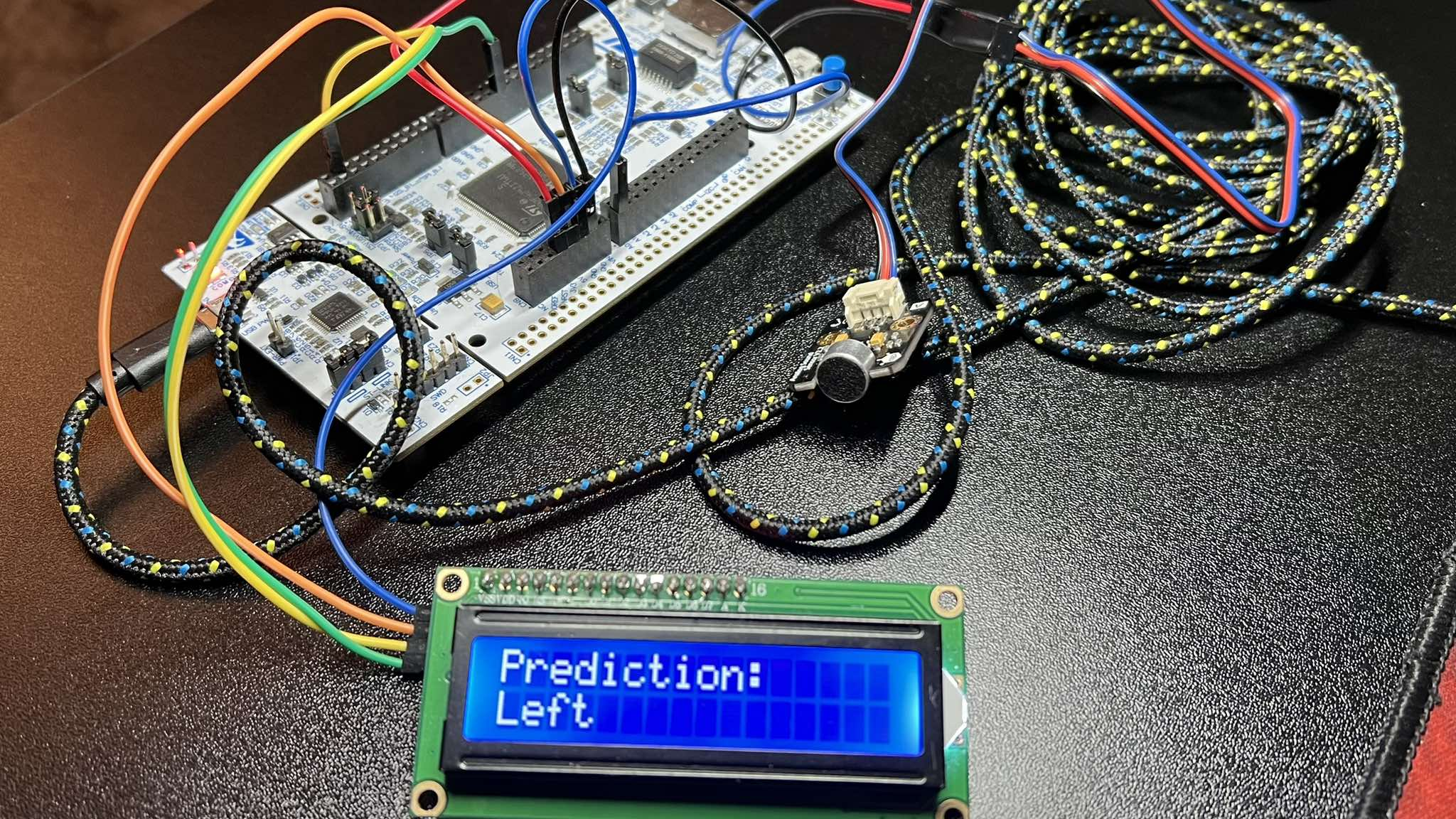
Projekt SpeechRecognition, powstały w ramach przedmiotu Technik Realizacji Cyfrowego Przetwarzania Sygnałów, zakładał stworzenie prostego systemu EdgeAI umożliwiajacego klasyfikację podstawowych komend głosowych, takich jak left, right, stop oraz go z wykorzystaniem sieci neuronowej umieszczonej na mikrokontrolerze STM32.
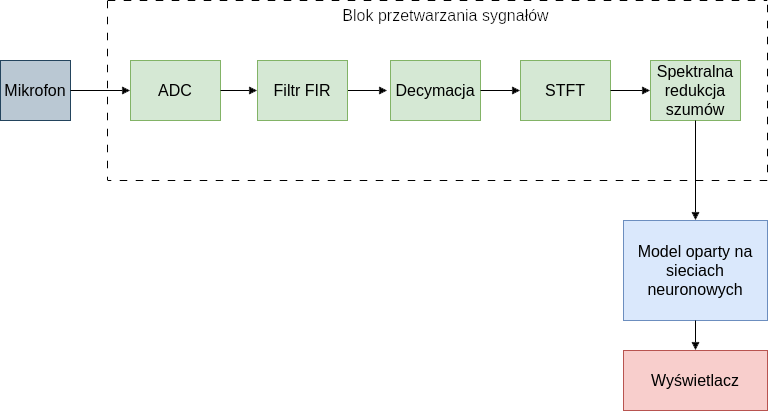
Na samym początku zdefinowana została architektura całego systemu, w której wyszczególnić można 3 elementy:
- akwizycja sygnału (mikrofon analogowy i próbkowanie z użyciem ADC)
- preprocesing audio (filtracja, decymacja do 8kHz, zamiana na spektrogram i eliminacja szumów spektralnych)
- klasyfikacja spektrogramów
Sieć neuronowa została wytrenowana z użyciem biblioteki Tensorflow w trybie offline na zbiorze danych speech commands. Poniżej przedstawiona została macierz pomyłek dla najlepszego modelu na danych testowych.

Najlepszy model został nastepnie dotrenowany na próbkach pochodzących z docelowego mikrofonu podłącoznego do mikrokontrolera, a liczba klas wyjściowych została zredukowana do 4. Przed konwersją na mikrokontroler STM32 z użyciem narzędzia X-Cube-AI sieć została dodatkowo zoptymalizowana i poddana procesowi kwantyzacji.
Poniżej przedstawiono wynik testów w postaci macierzy pomyłek dla całego systemu.
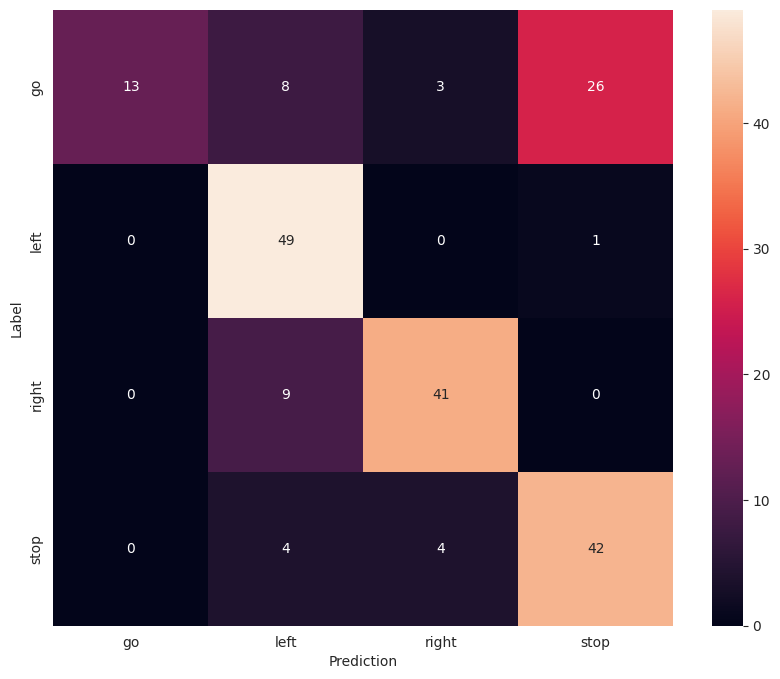
Skuteczność systemu mogłaby zostać poprawiona przy zastosowaniu mikrofonu MEMS z cyfrowym interfejsem I2S, zwiększeniu częstotliwości audio do fs=16kHz oraz zastosowaniu mikrokontrolera z większą ilością dostępnej pamięci SRAM.